The Unique Challenges of Programmatic PDF Translation
Developers often face significant hurdles when attempting to automate document translation, especially with the PDF format. Unlike plain text files, a PDF is a complex container that encapsulates text, fonts, vector graphics, and layout information. Directly extracting and translating text often breaks the document’s structure, resulting in a misaligned and unusable final product.
This process is fraught with technical difficulties that a simple text translation API cannot handle effectively.
The primary issue stems from the PDF’s fixed-layout nature, where text is positioned with precise coordinates rather than in a reflowable stream. A robust solution must be able to parse this structure, translate the textual content, and then meticulously reconstruct the document to mirror the original layout. Additionally, handling various text encodings, embedded fonts, and multi-column designs adds layers of complexity.
These challenges make a specialized document translation API not just a convenience, but a necessity for professional results.
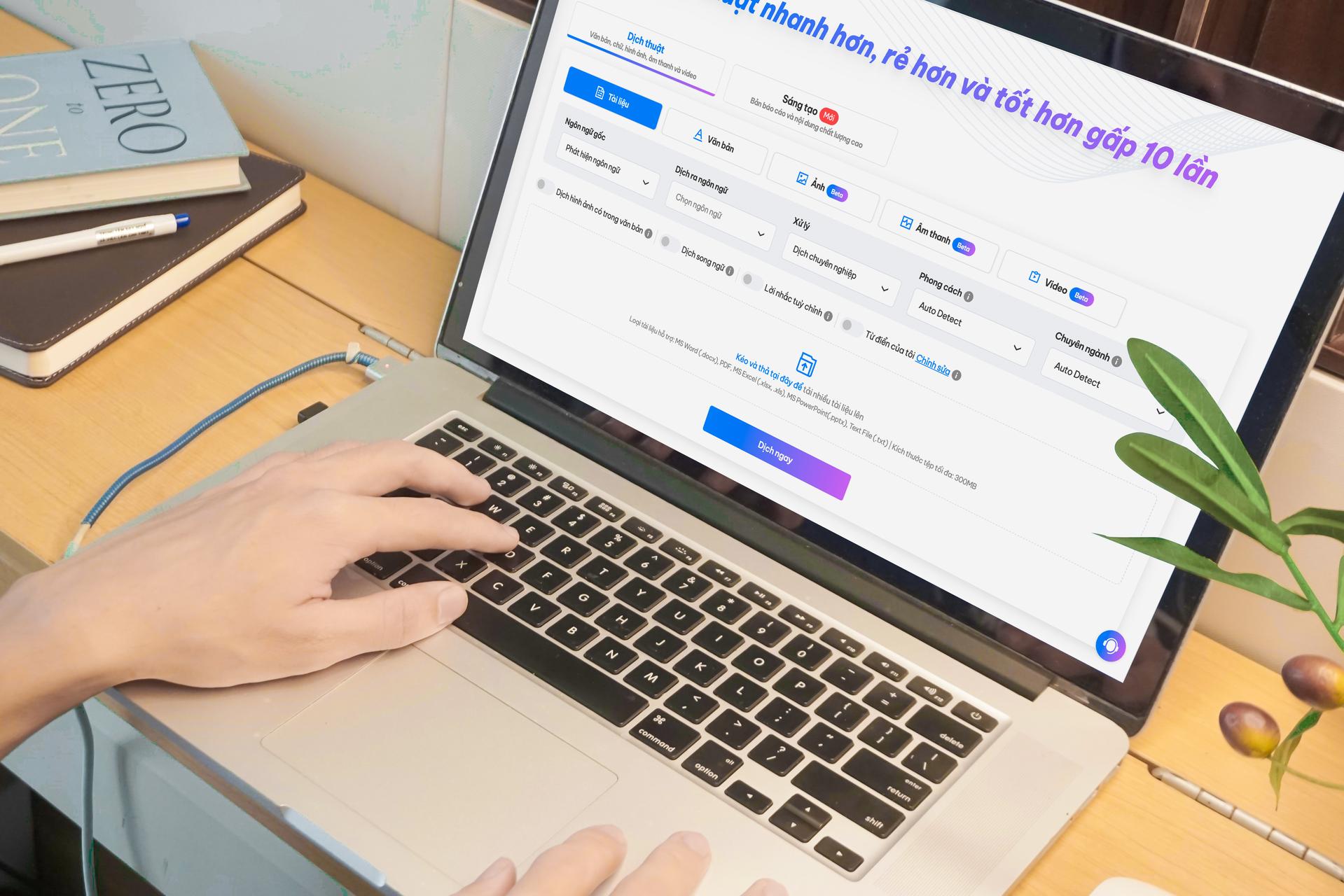
Introducing the Doctranslate API for PDF Translation
The Doctranslate API provides a powerful solution specifically designed to overcome these obstacles when you need to translate an English to Spanish PDF via an API. Built as a modern RESTful service, our API simplifies the entire workflow into a single, straightforward API call. Developers can programmatically submit documents and receive perfectly translated files that maintain their original formatting and layout.
This eliminates the need for complex parsing libraries or manual post-translation adjustments.
Our service handles the heavy lifting of PDF decomposition, text segment translation, and precise document reconstruction. It intelligently processes tables, lists, headers, footers, and columns to ensure the translated Spanish content fits naturally within the original design. For developers looking for a reliable way to translate documents while ensuring the layout and tables are perfectly preserved, our API offers an unparalleled advantage.
Step-by-Step Guide: Integrate our English to Spanish PDF API
Integrating our API into your application is a streamlined process designed for developer efficiency. This guide will walk you through the necessary steps using Python, a popular choice for scripting and backend services. You will learn how to authenticate, prepare your file, send the translation request, and handle the response.
Following these instructions will enable you to quickly add high-quality PDF translation capabilities to your projects.
Step 1: Authentication and Setup
Before making any API calls, you need to secure your unique API key from your Doctranslate dashboard. This key authenticates your requests and must be included in the request headers. We recommend storing this key securely as an environment variable rather than hardcoding it directly into your application source code.
For this Python example, you will also need to install the popular `requests` library by running `pip install requests` in your terminal.
Step 2: Preparing the API Request
To translate a document, you will send a `POST` request to our `/v2/document/translate` endpoint. This request must be formatted as `multipart/form-data`, as it includes the PDF file itself along with other parameters. The essential parameters are the file, the source language, and the target language.
You will specify `’en’` for English as the `source_lang` and `’es’` for Spanish as the `target_lang`.
The body of your request will contain several key-value pairs. The `file` key will hold the binary content of your English PDF. The `source_lang` and `target_lang` keys define the translation direction.
You can also include optional parameters like `bilingual` to create a side-by-side document, which can be incredibly useful for review processes or language learning applications.
Step 3: Sending the Request and Handling the Response with Python
With your API key and file ready, you can now construct and send the request. The Python script below demonstrates the complete process, from opening the file to sending the request and saving the translated result. Successful requests will return a `200 OK` status code, with the body of the response containing the binary data of the newly translated Spanish PDF.
It is crucial to handle the response correctly by writing its content to a new file with a `.pdf` extension.
import requests # Your unique API key from the Doctranslate dashboard API_KEY = 'your_api_key_here' # The path to your source PDF file file_path = 'path/to/your/document.pdf' # The Doctranslate API endpoint for document translation api_url = 'https://developer.doctranslate.io/v2/document/translate' # Set the headers with your API key for authentication headers = { 'Authorization': f'Bearer {API_KEY}' } # Prepare the data payload for the multipart/form-data request data = { 'source_lang': 'en', 'target_lang': 'es', } # Open the file in binary read mode and send the request with open(file_path, 'rb') as f: files = { 'file': (f.name, f, 'application/pdf') } print("Sending translation request...") response = requests.post(api_url, headers=headers, data=data, files=files) # Check if the request was successful if response.status_code == 200: # Save the translated PDF file with open('translated_document_es.pdf', 'wb') as translated_file: translated_file.write(response.content) print("Success! Translated PDF saved as translated_document_es.pdf") elif response.status_code == 422: # Handle validation errors (e.g., unsupported language pair) print(f"Validation Error: {response.json()}") else: # Handle other potential errors print(f"An error occurred: {response.status_code} - {response.text}")Key Considerations for Spanish Language Specifics
Translating content into Spanish involves more than just swapping words. The language has specific grammatical and cultural nuances that a high-quality translation engine must handle correctly. Understanding these details will help you appreciate the sophistication required for accurate document translation.
These factors are critical for producing professional-grade documents that resonate with native speakers.Character Encoding and Special Characters
Spanish uses several characters not found in the standard English alphabet, such as `ñ`, `ü`, and accented vowels (`á`, `é`, `í`, `ó`, `ú`). It is absolutely essential that your entire workflow, from file submission to processing the response, uses `UTF-8` encoding. Our API is built to handle these characters flawlessly, ensuring that all text is rendered correctly in the final translated PDF without corruption or replacement characters.
Grammatical Gender and Agreement
Unlike English, Spanish is a gendered language where nouns are either masculine or feminine. This grammatical gender affects the adjectives and articles that modify them, which must agree in both gender and number. A naive, word-for-word translation will often fail this test, leading to grammatically incorrect and unnatural-sounding sentences.
The Doctranslate API uses an advanced translation engine that understands these complex grammatical rules, ensuring that all agreements are correctly maintained throughout the document.Formality, Tone, and Regional Dialects
Spanish has different levels of formality, most notably the distinction between the informal `tú` and the formal `usted` for “you.” The correct choice depends entirely on the context and the intended audience, which is critical in business and technical documents. Our API supports a `tone` parameter, allowing you to guide the translation towards a more formal or informal style.
Furthermore, while the API produces a neutral Spanish suitable for a global audience, developers should be aware of regional vocabulary differences between Spain and Latin America when targeting a specific demographic.Conclusion: Simplify Your Translation Workflow
Integrating a powerful API to translate English to Spanish PDF documents is the most effective way to handle complex translation tasks at scale. The Doctranslate API removes the technical barriers associated with PDF parsing and layout reconstruction, providing a simple yet robust solution. By offloading this complexity, your development team can focus on building core application features rather than solving the intricate problems of document formatting.
This approach not only saves significant development time but also guarantees a higher quality, more professional final product. For more advanced features and a full list of parameters, be sure to explore our official developer documentation.

Để lại bình luận